Privacy Policy
Netkiller respects your concerns about privacy. References in this Privacy Policy to “Netkiller”, “we”, “us”, and “our” are references to the Netkiller entity responsible for the processing of your personal information, which generally is the Netkiller entity that collects your personal information.
This Privacy Policy describes the types of personal information we obtain, how we may use that personal information, with whom we may share it and how you may exercise your rights regarding our processing of that information. The Privacy Policy also describes the measures we take to safeguard the personal information we obtain and how you can contact us about our privacy practices.
This Privacy Policy applies to the personal information we obtain through Netkiller properties, including websites, products, services, desktop and mobile apps, and other tools offered by Netkiller that reference this Privacy Policy (“Online Services”); offline collection, including Netkiller events, surveys, questionnaires, customer user research and evaluations (“Offline Channels”); and third-party sources, including business partners, ad networks and vendors (collectively, the “Offerings”). This Privacy Policy does not apply to other Netkiller products and services that post separate privacy policies.
In connection with providing support, cloud and other services, Netkiller processes certain data maintained in environments that Netkiller may access to perform cloud, consulting and support services (“Customer Content”) on behalf of and at the direction of its customers and partners, as well as log data (e.g., regarding access and authentication requests) that we collect for analysis and security purposes across our services. Our use of such Customer Content and log data is subject to the terms of our customer agreements and is not governed by this Privacy Policy. In contrast, the information we collect through our customers’ and partners’ use of our websites (such as names, addresses, billing information and employee contact information) and through our offline interactions with customers and partners is subject to the terms of this Privacy Policy.
The Online Services may provide links to other third-party websites and features. Some of these third-party websites may be co-branded with a Netkiller logo even though they are not owned, controlled, operated or maintained by Netkiller. Netkiller does not share your personal information with those websites and is not responsible for their privacy practices. These websites are subject to their respective privacy policies. In some cases, we may provide the Offerings jointly with other businesses. For these co-branded offerings in which a third party is involved in your transactions, we will sometimes share or jointly collect customer data related to those transactions with that third party.
Personal Information We Obtain
The data we obtain varies based on the Offerings you use. We obtain personal information through your interaction with the Offerings, such as when you:
create an account in an Online Service;
register or apply to a Netkiller partner program;
sign up for an online program, event, seminar, promotion or sweepstakes;
request products (including product evaluations, trials, tech preview and beta downloads), services or information;
participate in Netkiller events, surveys, questionnaires, research or evaluations; or
correspond with us or request information from us.
The types of personal information we obtain include:
contact information (such as name email address, telephone number, postal or other physical address) for you or for others (e.g., principals in your business or billing contacts);
information used to create your online account (such as username and password);
biographical and demographic information (such as gender, job title/position and occupation);
business profile and practices information used to evaluate you as a partner;
photographs;
billing and financial information (such as name, billing address, payment card details and bank account information and purchase history);
information you submit in connection with a career opportunity at Netkiller, such as contact details, information in your résumé (including work history, education and language skills) and details about your current employment;
location data (such as data derived from your IP address, country and zip code);
clickstream data and other information about your online activities (such as information about your devices, browsing actions and usage patterns), including across the Online Services and third-party websites, that we obtain through the use of cookies, web beacons and similar technologies (see our description of Cookies and Similar Technologies below);
personal information contained in forums, blogs, and testimonials you provide or that we obtain from publicly available sources (such as social media channels);
information related to participation in classroom or online training, including programs completed and certifications achieved;
information necessary to provide support or other paid consulting services (such as contact details, chat services, support details, and event history);
personal information contained in content you submit to us (such as through our “Contact” feature or other in-product or in-service messaging); and
other personal information we obtain through our Offerings.
Please note that providing personal information to us is voluntary on your part. If you choose not to provide us certain information, we may not be able to offer you certain products and services, and you may not be able to access certain features of the Online Services.
How We Use Personal Information
We use the information we obtain to:
provide and administer our products and services (including websites and apps for which you have registered);
process and fulfill orders in connection with our products and services and keep you informed about the status of your order;
help you complete a transaction or order and provide customer support;
bill you for products and services you purchased;
provide training, support and consulting services;
manage career opportunities, including for recruitment purposes, employee onboarding and other Human Resources purposes;
create and manage your account with Netkiller;
operate, evaluate and improve our business (such as by administering, developing, enhancing and improving our products and services; managing our communications and customer relationships; and performing accounting, auditing, billing, reconciliation and collection activities);
perform data analytics (such as research, trend analysis, financial analysis and customer segmentation);
communicate with you about your account and orders (including sending emails relating to your registration, account status, order confirmations, renewal or expiration notices and other important information);
conduct marketing and sales activities (including sending you promotional materials, generating leads, pursuing marketing prospects, performing market research, determining and managing the effectiveness of our advertising and marketing campaigns and managing our brand);
communicate with you about, and administer your participation in, events, programs, promotions and surveys;
connect employees with their enterprise account administrator;
verify your identity and protect your account against unauthorized use or abuse of our services;
protect against, identify and prevent fraud and other unlawful activity, claims and other liabilities;
comply with and enforce relevant industry standards, contractual obligations and our policies;
maintain and enhance the security of our Online Services, products, services, network services, information resources and employees; and
respond to your inquiries.
Depending on the purposes for which personal information is used, and the context in which the data is obtained, we may rely on one or more of the following legal bases:
performance of a contract with you or a relevant party;
our legitimate business interests;
compliance with a legal obligation, a court order, or to exercise or defend legal claims; or
your consent to the processing, which you can revoke at any time.
We may combine data collected from you with other sources to help us improve the accuracy of our marketing and communications as well as to help expand or tailor our interactions with you. This includes combining personal information we obtain through Online Services with information we obtain through Offline Channels, as well as other information (such as referral programs), for the purposes described above. We may anonymize or aggregate personal information and use it for the purposes described above and for other purposes to the extent permitted by applicable law. We also may use personal information for additional purposes that we specify at the time of collection. We will obtain your consent for these additional uses to the extent required by applicable law.
Where required by applicable law, we will obtain your consent for the processing of your personal information for direct marketing purposes.
Cookies and Other Technologies
Netkiller uses cookies, web beacons (including pixels and tags), and similar technologies on our Online Services that collect certain information about you by automated means. A “cookie” is a text file that websites send to a visitor’s computer or other Internet-connected device to uniquely identify the visitor’s browser or to store information or settings in the browser. A “web beacon,” also known as an Internet tag, pixel tag or clear GIF, links web pages to web servers and their cookies and may be used to transmit information collected through cookies back to a web server.
We use these automated technologies to collect information about your equipment, browsing actions, and usage patterns. The information we obtain in this manner includes IP address and other identifiers associated with your devices, types of devices connected to our Offerings, device characteristics (such as operating system), language preferences, referring/exit pages, navigation paths, access times, browser preferences and characteristics, installed plugins, local time zones, local storage preferences, clickstream data and other information about your online activities. We use on our Online Services both first-party cookies (served directly by our website domain when you visit our Online Services) and third-party cookies (served by a third-party website when you visit our Online Services and certain third-party websites with whom we have partnered). Some of these cookies are session cookies (which are automatically deleted when you close your browser) and others are persistent cookies (which remain on your computer or other Internet-connected device for a period of time after you end your browsing session, unless you delete them).
The cookies we use on our Online Services include (1) essential and functional cookies; (2) analytics cookies; and (3) targeting/advertising cookies, as described below.
Essential and Functional Cookies
We use cookies on our Online Services that are necessary for us to provide you with our products and services. This includes essential cookies (such as those used to authenticate you to our website and identify you after you have logged in), functional cookies (such as those that remember what you added to your shopping cart or the language preference you selected), and user-centric security cookies used to increase the security of the products and services we provide to you (such as to detect authentication abuses). Given the necessary functionality of these cookies, they typically may not be disabled on our Online Services.
Analytics Cookies
We use analytics cookies to collect information on how users navigate and use our Online Services, such as how the users traverse our Online Services, the pages they view, how long they stay on a page and whether the page is displayed correctly or whether errors occur. Such cookies help us to improve the performance of our Online Services and make the Online Services more user-friendly. These cookies are provided by third-party analytics providers, including Google Analytics and Marketo. To learn more about Google Analytics and how to opt out, please visit Google Analytics. To learn more about these analytics services and how to opt out, please view our Cookie Consent Tool here.
How We Share Your Personal Information
We do not sell or otherwise disclose personal information about you except as described here or at the time of collection. Netkiller may share personal data in the following ways:
if sharing your data is necessary to provide a product, service or information you have requested;
- as part of a joint sales promotion or to pass sales leads to our business partners;
- to keep you up to date on the latest product announcements, software updates, special offers or other information we think you would like to hear from our business partners;
- within Netkiller (including among affiliates and subsidiaries) for the purposes described in this Privacy Policy;
- for the purposes of validating employment, training completed or product certifications achieved;
- to connect employees with their company administrator(s);
- with our customers to report and help manage issues requiring support or as part of consulting services;
- with our customers and partners to inform them about their users’ use of our services (such as when a user has obtained credentials or completed a course);
- with service providers we have engaged to perform services on our behalf (such as payment processing, order fulfillment, customer support, customer relations management and data analytics). These service providers are contractually required to safeguard the information provided to them and are restricted from using or disclosing such information except as necessary to perform services on our behalf or to comply with legal requirements;
- with approved Netkiller partners, to offer and provide our products and services to you; and
- with our joint marketing and sales partners and other business partners who help us with our business operations or other aspects of our business and for the purposes described in this Privacy Policy.
We also may disclose personal information about you (1) if we are required or permitted to do so by applicable law, regulation or legal process (such as a court order or subpoena), (2) to law enforcement authorities or other government officials to comply with a legitimate legal request, (3) when we believe disclosure is necessary to prevent physical harm or financial loss to Netkiller, its users or the public as required or permitted by law, (4) to establish, exercise or defend our legal rights, and (5) in connection with an investigation of suspected or actual fraud, illegal activity, security or technical issues.
In addition, we reserve the right to transfer to relevant third parties information we have about you in the event of a potential or actual sale or transfer of all or a portion of our business or assets (including in the event of a merger, acquisition, joint venture, reorganization, divestiture, dissolution or liquidation) or other business transaction.
We also may share the information in other ways for which we provide specific notice at the time of collection and obtain your consent to the extent required by applicable law.
International Data Transfers
We transfer the personal information we collect through the Channels to, and store such data in, other countries in which Netkiller and its service providers operate, including the U.S., which may have different data protection laws than the country in which the information was provided. If we do so, we will transfer the personal information only for the purposes described in this Privacy Policy. To the extent required by applicable law, when we transfer your personal information to recipients in other countries, we will take measures to protect that information including, as appropriate, by executing data transfer agreements based on the European Commission’s Standard Contractual Clauses pursuant to article 46 of the General Data Protection Regulation (GDPR), or by selecting data recipients that are certified to the EU-U.S. and Swiss-U.S. Privacy Shield frameworks described below.
EU-U.S. and Swiss-U.S. Privacy Shield
With respect to transfers of personal information from the EU and Switzerland to the U.S., Netkiller is certified under the EU-U.S. Privacy Shield Framework and Swiss-U.S. Privacy Shield Framework as set forth by the U.S. Department of Commerce and the European Commission regarding the transfer of personal information from the EU to the U.S., pursuant to article 45 of the GDPR (each a “Privacy Shield Framework” and collectively the “Privacy Shield Principles”). If there is any conflict between the terms of this Privacy Policy and the Privacy Shield Principles, the Privacy Shield Principles shall govern. To learn more about the Privacy Shield program, and to view our certification, please visit https://www.privacyshield.gov/.
Netkiller is responsible for the processing of personal information it receives, under each Privacy Shield Framework, and subsequently transfers to a third party acting as an agent on its behalf. Netkiller complies with the Privacy Shield Principles for all onward transfers of personal information from the EU and Switzerland, including the onward transfer liability provisions.
With respect to personal information received or transferred pursuant to a Privacy Shield Framework, Netkiller is subject to the regulatory enforcement powers of the U.S. Federal Trade Commission. In certain situations, Netkiller may be required to disclose personal information in response to lawful requests by public authorities, including to satisfy national security or law enforcement requirements.
Under certain conditions, more fully described on the Privacy Shield website, you may invoke binding arbitration when other dispute resolution procedures have been exhausted.
In compliance with the Privacy Shield Principles, Netkiller commits to resolve complaints about our collection or use of your personal information. If you have questions or complaints regarding our Privacy Policy or practices, please contact us.
EU and Swiss individuals with inquiries or complaints regarding our Privacy Shield policy should first contact Netkiller. If you have an unresolved complaint that has not been addressed to your satisfaction, please contact or visit https://feedback-form.truste.com/watchdog/request (a U.S.-based alternative dispute resolution provider) for more information or to file a complaint. The services are provided at no cost to you.
Netkiller has further committed to cooperate with the panel established by the EU data protection authorities (DPAs) and the Swiss Federal Data Protection and Information Commissioner (FDPIC) with regard to unresolved Privacy Shield complaints concerning human resources data transferred from the EU and Switzerland in the context of the employment relationship.
Your Rights and Choices
We offer you certain choices in connection with the personal information we obtain about you, such as how we use the information and how we communicate with you. To update your preferences, limit the communications you receive from us or submit a request, please contact us as specified in the How to Contact Us section of this Privacy Policy. You can also unsubscribe from our mailing lists by following the “Unsubscribe” link in our emails.
To the extent provided by the law of your jurisdiction, you may request access to the personal information we maintain about you or request that we correct, update, amend or delete your information, or that we restrict the processing of such information by contacting us as indicated below or by accessing MyAccount. To help protect your privacy and maintain security, we may take steps to verify your identity before granting you access to the information. To the extent permitted by applicable law, a charge may apply before we provide you with a copy of any of your personal information that we maintain. Depending on your location, you may have the right to file a complaint with a government regulator if you are not satisfied with our response.
We support the Self-Regulatory Principles for Online Behavioral Advertising (“Principles”) of the Digital Advertising Alliance in the U.S., the Digital Advertising Alliance of Canada, and the European Digital Advertising Alliance in the EU. If you live in the United States, Canada, or the European Union, you can visit
Ad Choices, Ad Choices Canada or Your Online Choices to find a convenient place to indicate your preferences, including the option to make one “universal” opt-out of interest-based advertising with participating entities. These websites also provide detailed information about interest-based advertising and tips for managing your privacy online and in applications. Opting out of interest-based advertising does not mean you will no longer see advertisements from us or on the Online Services; rather, opting out means that the online ads that you do see will not be based on your interests. When you opt-out of receiving interest-based advertisements through the links above, cookies and other technologies on the Online Services may still collect information about your use of the Online Services, including for analytics, fraud prevention and any other purpose permitted under the Self- Regulatory Principles.
When you use our Online Services, both we and certain third parties (such as our advertising networks, digital advertising partners and social media platforms) may collect personal information about your online activities, over time and across third-party websites. Certain web browsers allow you to instruct your browser to send Do Not Track (“DNT”) signals to websites you visit, informing those sites that you do not want your online activities to be tracked.
Where provided by law, you may withdraw any consent you previously provided to us or object at any time on legitimate grounds to the processing of your personal information, and we will apply your preferences going forward. This will not affect the lawfulness of our use of your information based on your consent before its withdrawal.
In order to learn more about your rights under California Consumer Privacy Act(CCPA), please see our CCPA Policy.
How We Protect Personal Information
We maintain administrative, technical and physical safeguards, consistent with legal requirements where the personal information was obtained, designed to protect against unlawful or unauthorized destruction, loss, alteration, use or disclosure of, or access to, the personal information provided to us through the Channels.
Retention of Personal Information
To the extent permitted by applicable law, we typically retain personal information we obtain about you for as long as it is needed (1) for the purposes for which we obtained it, in accordance with the terms of this Privacy Policy, which generally means that we will keep your personal information for the duration of our relationship or as long as you keep your account open with us; or (2) to take into account applicable statute of limitation periods and comply with applicable laws, resolve disputes and enforce our agreements. As described in the “Your Rights and Choices” section above, to the extent provided by the law of your jurisdiction, you may request that we delete your information or restrict the processing of such information by contacting us as indicated below.
Notice to California Residents
Subject to certain limits under California law, California residents may ask us to provide them with (1) a list of certain categories of personal information we have disclosed to third parties for their direct marketing purposes during the immediately preceding calendar year and (2) the identity of those third parties. To obtain this information, please send an email to privacy@Netkiller.com with “California Shine the Light Privacy Request” in the subject line and in the body of your message.
Children’s Personal Information
The Online Services are designed for a general audience and are not directed to children under the age of 16. We do not knowingly collect or solicit personal information from children under the age of 16 through the Online Services. If we become aware that we have collected personal information from a child under the age of 16, we will promptly delete the information from our records. If you believe that a child under the age of 16 may have provided us with personal information, please contact us as specified in Contact Us section of this Privacy Policy.
Changes to Our Privacy Policy
This Privacy Policy may be updated periodically and without prior notice to you to reflect changes in our information practices. We will indicate at the top of this Privacy Policy when it was most recently updated. We encourage you to periodically review this Privacy Policy for the latest information on our privacy practices.
How to Contact Us
If you have any questions or comments about this Privacy Policy or if you would like us to update information we have about you or your preferences, please contact us by email at privacy@Netkiller.com or write to us at:
Netkiller, Inc. | Netkiller Co., Ltd.
Attn: Chief Privacy & Digital Risk Officer / Data Protection Officer
3031 Tisch Way, San Jose, CA 95128, USA | 6425 Living Place, Bakery office bldg #2, Pittsburgh, PA 15206, USA | 8F, 7, Teheran-ro 5-gil, Gangnam-gu, South Korea, ZIP 06134
Communication Plan
Objective:
This document is designed to provide awareness of the ISMS, provide instruction on how the ISMS is communicated and used throughout the Netkiller organization, and help personnel apply the ISMS to their roles. This document will also describe the potential consequences of failure to follow the guidelines set forth in the ISMS.
If you’re an employee looking for information to provide customers/vendors/etc:
The Continuity / ISMS Summary is typically provided to external parties as a supplement when they are interested in the broader details of the information security systems we use. We can answer external requests for more information by forwarding them to legal or compliance, who will supply further information at their discretion.
What is the ISMS? What does it do?
The Netkiller Information Security Management System (ISMS) is a system comprised of documents, policies, procedures, cultural values and best practice habits that have been Implemented by Top Management to satisfy two main objectives:
A reliable service to the customer, 99.999% of the time.
A secure service provided to the customer, defined as a collection of metrics and practices measuring security related issues
The ISMS is designed to be compliant to ISO/IEC 27001:2013 2nd Ed 2013-10-01 which is a set of requirements that Netkiller has adopted in order to build and maintain a functional ISMS with the end goal of a continually improved upon security approach. For a copy of (or guidance with) this standard please refer to the Compliance Specialist.
Who does this apply to?
Everyone in the company is involved to some extent in the success of the ISMS, and in turn the success of the company. That being said, most people will only need a basic understanding of the ISMS, and know how their role applies to its success. In order to get a basic understanding across to the company, this document was created. In the table below, you can find the departments in Netkiller, and their expected level of involvement with the ISMS.
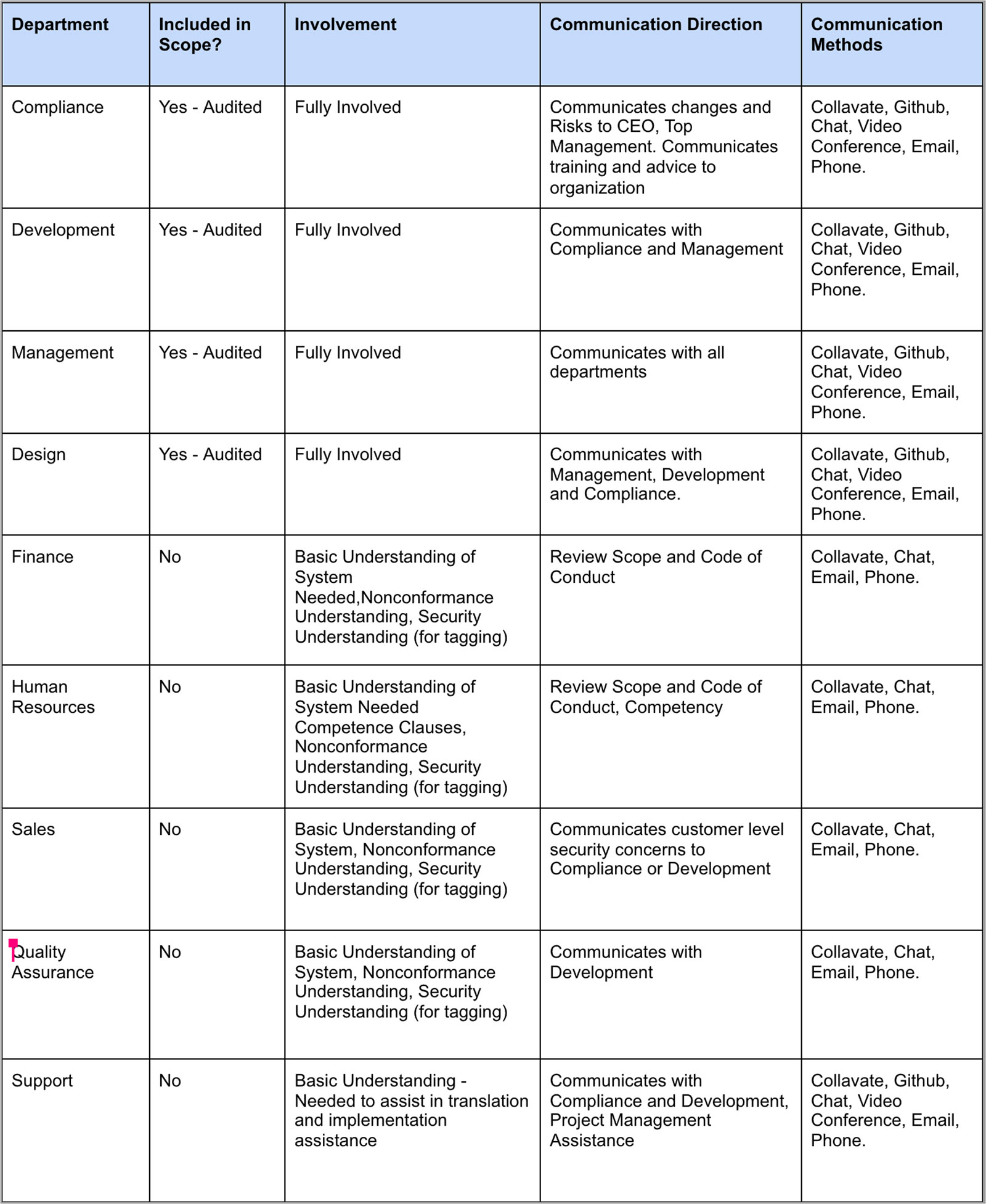
The chart says I’m not fully involved, and I won’t get audited, should I stop reading?
No, just because your department does not get audited doesn’t mean you don’t contribute to the success of the system!
For example, if you don’t know how we control our risks, you won’t know how to help prevent risks, and the business might miss a huge opportunity to patch a bug or fix an issue! Also, knowingly ignoring a policy or practice mandated by the ISMS can result in negative consequences for both the employee and the business. If you know something in the ISMS isn’t being followed, please report it as a nonconformity.
For this reason, everyone at Netkiller should, at a minimum, read and understand the following documents:
Also, everyone should know how to:
Access the ISMS Dashboard (This provides a lot of detail, and is best used alongside compliance to help you navigate it for the first time.
Report a Security Issue (For KillerID and NetkillerDLP)
Report a Nonconformance (For KillerID and NetkillerDLP)
Report a Bug (For KillerID and NetkillerDLP)
Request an Enhancement/Improvement (For KillerID and NetkillerDLP)
If you aren’t sure how to do these things, we have instructions for you here:
How to report Nonconformances, Bugs, Security Issues, and Make Improvements
Is there a forum to ask questions?
There is a continuing internal discussion on the ISMS, located in Netkillers Dedicated ISMS Group. To get access, just ask!
Who can I ask about the ISMS groups and other areas?
Compliance can point you in the right direction, just email us! (Matthew.lockmer@netkiller.com)
(Matthew.lockmer@netkiller.com)
What is the process for how these policies are created?
It is best shown as a graphic, below:
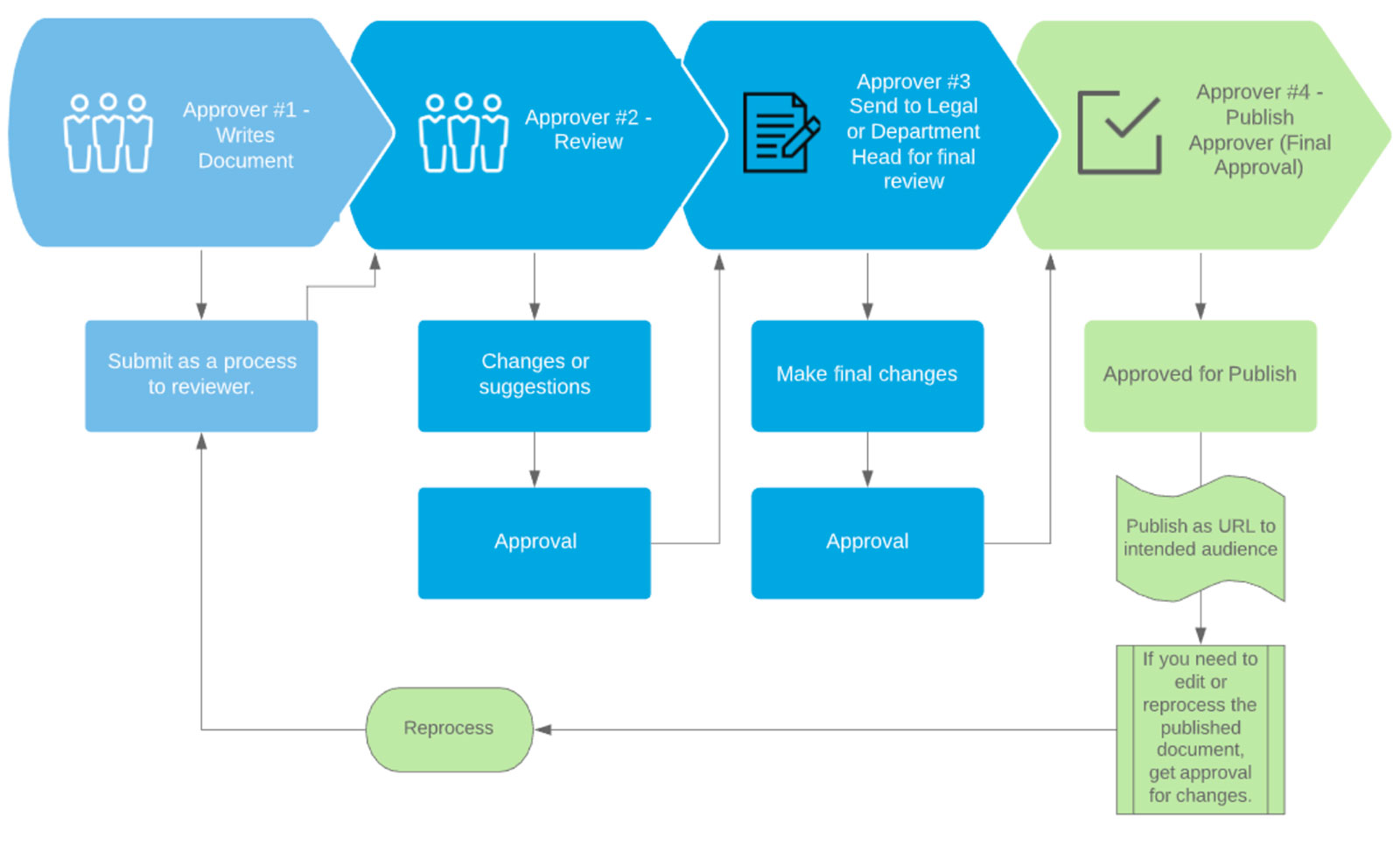
As you can see, an ISMS document only exists because Top Management believes it supports the objectives of the business, and so all ISMS policies are to be considered directives from Top Management to all employees.
Security Policy
Introduction
Netkiller fully understands the security implications of the cloud software model. Our cloud Software is designed to deliver better security than many traditional on-premises solutions. We make security a priority to protect our own operations, but because Netkiller runs on the same software that we make available to our customers, your organization can directly benefit from these protections. That’s why we focus on security, and protection of data is among our primary design criteria.
Security drives our organizational structure, training priorities and hiring processes. It shapes our data and the technology they house. It’s central to our everyday operations and disaster planning, including how we address threats. It’s prioritized in the way we handle customer data.
And it’s the cornerstone of our account controls, our compliance audits and the certifications we offer our customers.
This paper outlines Netkiller’s approach to security and compliance for Netkiller Cloud Software and services. Used by organizations worldwide, from large enterprises and retailers with hundreds of thousands of users to fast-growing startups. This policy focuses on security including details on organizational and technical controls regarding how Netkiller protects client and internal data.
Netkiller Has a Strong Security Culture
Netkiller has created a vibrant and inclusive security culture for all employees. The influence of this culture is apparent during the hiring process and employee onboarding, as part of ongoing training and in company-wide events to raise awareness.
Employee background checks
Before they join our staff, Netkiller will verify an individual’s background and previous employment, and perform internal and external reference checks as well as several onsite/video interviews. Where local labor law or statutory regulations permit, Netkiller may also conduct criminal, credit, immigration, and security checks. The extent of these background checks is dependent on the desired position, and may vary from role to role. The extent to which a role is checked is determined by the CEO and/or Hiring Manager for that position. Typically, most positions require one or more of the following: a background check, reference check, and employment verification. Positions at the Officer (VP) level and higher may receive a deeper verification at the discretion of the CEO. The hiring manager for the position communicates these requirements with the CEO when the CEO decides to hire for a position. Most positions outside of the USA are hired through upwork.com, where contracts and employee references can be seen.
Security training for all employees
All Netkiller employees undergo security training as part of the orientation process and receive ongoing security training throughout their Netkiller careers. During orientation, new employees agree to our Code of Conduct, which highlights our commitment to keep customer information safe and secure. Depending on their job role, additional training on specific aspects of security may be required. For instance, the information security team instructs new developers on topics like secure coding practices, product design and automated vulnerability testing tools.
2020 Netkiller Security Awareness Training
2020 Netkiller Security Training Assessment
Internal security and privacy events
Netkiller hosts regular internal conferences to raise awareness and drive innovation in security and data privacy, which are open to all employees. Security and privacy is an ever-evolving area, and Netkiller recognizes that dedicated employee engagement is a key means of raising awareness.
Our dedicated security team
Netkiller employs security and privacy professionals, who are part of our software engineering and operations division. Our team includes Netkiller CEO Justin Jung, one of foremost security experts in information, application and network. This team is tasked with maintaining the company’s defense systems, developing security review processes, building security infrastructure and implementing Netkiller’s security policies.
Netkiller’s dedicated security team actively scans for security threats using commercial and custom tools, penetration tests, quality assurance (QA) measures and software security reviews. Within Netkiller, members of the information security team review security plans for all networks, systems and services. They provide project-specific consulting services to Netkiller’s product and engineering teams when needed, applying ISMS and project specific security when needed. They monitor for suspicious activity on Netkiller’s networks, address information security threats, perform routine security evaluations and audits, and engage outside experts to conduct regular security assessments. In the event of a privacy or data breach that is caused by an internal employee, the employee will be suspended pending further investigation into the nature and intention of the breach, and appropriate parties and authorities shall be notified.
Our dedicated privacy team
The Netkiller privacy team operates separately from product development and security organizations, but participates in every Netkiller product launch by reviewing design documentation and performing code reviews to ensure that privacy requirements are followed. They help release products that reflect strong privacy standards: transparent collection of user data and providing users and administrators with meaningful privacy configuration options, while continuing to be good stewards of any information stored on our platform. After products launch, the privacy team oversees automated processes that audit data traffic to verify appropriate data usage. In addition, the privacy team conducts research providing thought leadership on privacy best practices for our emerging technologies.
Internal audit and compliance specialists
Netkiller has a dedicated internal audit team that reviews compliance with security laws and regulations around the world. As new auditing standards are created, the internal audit team determines what controls, processes, and systems are needed to meet them. This team facilitates and supports independent audits and assessments by third parties. In 2019, a dedicated compliance specialist was hired to design, manage, and direct Netkiller’s ISMS and Compliance Activities.
Risk Scoring
Calculating Risk Score:
Risk = Vulnerability x Threat x Impact
Min Score is 1
Max Score is 125
Vulnerability, Threat,Impact are determined on a scale of 1-5. The lowest being 1, and the highest represented by 5. These are then multiplied to determine the risk score.
Risk Scores are used to calculate the approximate criticality of a given risk. Any risk with a score over 100 is considered a high priority and reviewed by management via virtual conference at the earliest possible date. The nature and sometimes potential cost of the risk is discussed to see if resources are needed to mitigate the risk. Netkiller treats all risks, regardless of score. Typically netkiller will not elect to tolerate risk scores over 100, at the discretion of the CEO exceptions can be made.
Reports of Breaches, security events that need investigated, and requests for information about the ISMS or its policies should be directed to
matthew.lockmer@netkiller.com
412-952-1107
Matthew is available 24/7 for critical emergencies, but is best reached during EST 9am-5pm.
Business Continuity Plan
We believe that business continuity is the ability to maintain operations/services in the face of a disruptive event.
This requires the availability of computing, application services, physical network access, and network services, as well as user/client access to this infrastructure.
Netkiller maintains continuity in operations and services, including systems such as Web servers, email, critical databases, and so forth, requiring specific technology. This technology and infrastructure can include Cloud, virtualization, clustering/failover/failback, server hardware, network, and networking services, remote datacenter facilities, replication services, and redundant shared storage.
Depending on the type of event, continuity of a given application is achieved by failing over its services and user/client access locally within the same datacenter or to remote, physically disparate data center which is provided by Google Cloud Platform(GCP).
With the Netkiller business continuity plan, the failover of a service is measured in seconds or less. Backup technologies, including those that rely on a disk as a backup target, cannot provide this level of continuity of services. Backups, in order to be used, require a restoration process and are typically used for disaster recovery purposes.
Contacts With Authorities
In the event of an emergency or security incident, Netkiller has both internal and external contacts. Internal emergency contacts can be located here, for any and all emergencies, contact Justin Jung after alerting the appropriate local/federal bodies.
For all breaches, we follow California’s breach reporting regulations. You can find CA regulations here.
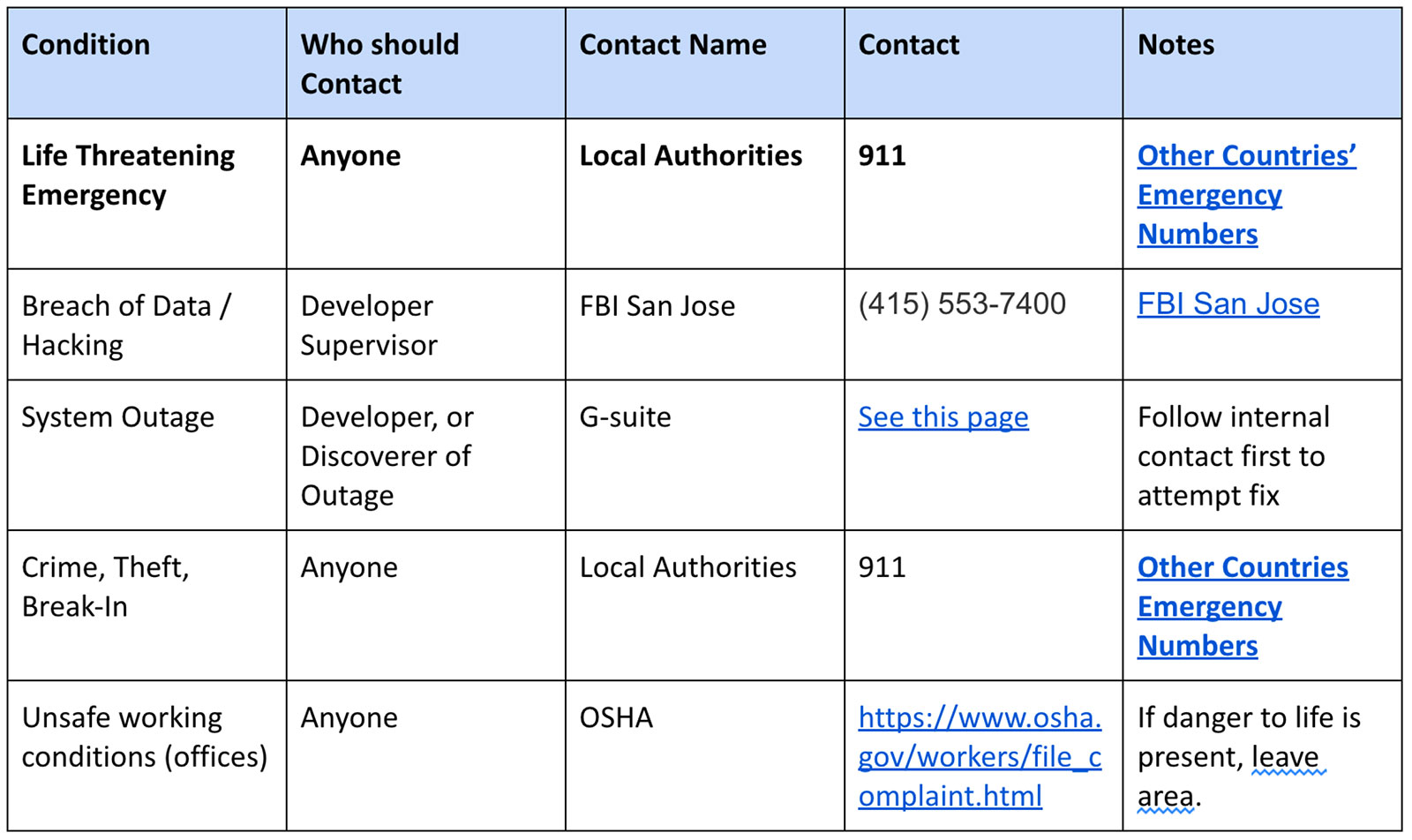
Additional Contingencies can be found here
Netkiller emergency contact numbers can be found here
Our business impact analysis template (above this one) is designed for companies to establish a clear plan of action after a disruption in normal business processes. Through both qualitative and quantitative business operation variables, a BIA collects information to develop a targeted recovery strategy to maintain productivity and business continuity. These variables include recovery time objective (RTO), recovery point objective (RPO), and maximum tolerable downtime (MTD). By identifying the severity of impact, resource requirements, and recovery priorities, a company can minimize its recovery time. After these initial components are established, the BIA can assess the financial and operational impacts based on the levels of severity afflicted on business units, departments, and processes.
Disaster Recovery
Phase I – Data Collection
The project should be organized with timeline, resources, and expected output
The business impact analysis should be conducted at regular intervals
Risk assessment should be conducted regularly
Onsite and Offsite Backup and Recovery procedures should be reviewed
Alternate site location must be selected and ready for use
Phase II – Plan Development and Testing
Development of Disaster Recovery Plan
Testing the plan
Phase III – Monitoring and Maintenance
Maintenance of the Plan through updates and review
Periodic inspection of DRP
Documentation of changes
IT Network Disaster Recovery
Objective
The statement of the objective including project details, Onsite/Offsite data, resources, and business type
Disaster Recovery Plan Criteria
A documentation of the procedures as to declaring an emergency, evacuation of the site pertaining to nature of the disaster, active-backup, notification of the related officials/DR team/staff, notification of procedures to be followed when disaster breaks out, alternate location specifications, should all be maintained. It is beneficial to be prepared in advance with sample DRPs and disaster recovery examples so that every individual in an organization is better educated on the basics.
DR Team – Roles and Responsibilities
Documentation should include identification and contact details of key personnel in the disaster recovery team, their roles and responsibilities in the team.
Contingency Procedures
The routine to be established when operating in contingency mode should be determined and documented. It should include an inventory of systems and equipment in the location; descriptions of the process, equipment, software; minimum requirements of the processing; location of vital records with categories; descriptions of data and communication networks, and customer/vendor details. Resource planning should be developed for operating in emergency mode. The essential procedures to restore normalcy and business continuity must be listed out, including the plan steps for recovering lost data and to restore normal operating mode.
Testing and Maintenance
The dates of testing, disaster recovery scenario, and plans for each scenario should be documented. Maintenance involves a record of scheduled reviews on a daily, weekly, monthly, quarterly, yearly basis; reviews of plans, teams, activities, tasks accomplished, and complete documentation review and update.
The disaster recovery plan developed thereby should be tested for efficiency. To aid in that function a test strategy and corresponding test plan should be developed and administered. The results obtained should be recorded, analyzed, and modified as required. Organizations realize the importance of business continuity plans that keep their business operations continuing without any hindrance. Disaster recovery planning is a crucial component of today’s
network-based organizations that determine productivity, and business continuity
Netkiller adapts Google’s Disaster Recovery Guideline
When it comes to disaster recovery, there’s no silver bullet—that is, no single recovery plan can cover all use cases. This article provides guidance for handling a variety of disaster recovery scenarios using Google’s cloud infrastructure.
Terminology
This article uses the following terms:
The recovery time objective (RTO), which is the maximum acceptable length of time that your application can be offline. This value is usually defined as part of a larger service level agreement (SLA).
A recovery point objective (RPO), which is the maximum acceptable length of time during which data might be lost due to a major incident. Note that this metric describes the length of time only; it does not address the amount or quality of the data lost.
Scenarios
This section explores common disaster recovery scenarios and provides recovery strategies and example implementations on Google Cloud Platform for each.
Historical data recovery
Historical data most often needs to be archived for compliance reasons, but it is also commonly archived for use in future historical analysis. In both cases, it’s important to archive relevant log and database data in a durable way using an easily accessible and transformable format.
Typically, historical data has a medium or large RTO. However, as it is expected to be complete and accurate, historical data tends to have a small RPO.
Archiving log data
Log data is usually used for historical trend analysis and for potential forensic analysis. Generally, this data does not need to be stored for years. However, as noted earlier, it’s important that this data can be easily imported into a format that lends itself to analysis.
Google Cloud Platform provides several options for exporting log data, including:
Stream to Google Cloud Storage bucket, which periodically writes your logs to Cloud Storage. The files are timestamped, encrypted, and stored in appropriately-named folders, making it simple to locate logs from a given time period.
Stream to BigQuery dataset, which streams your logs to a BigQuery dataset. BigQuery stores data in an immutable, read-only manner.
For details on exporting logs, see Exporting Your Logs.
Archiving database data
Relational database backups often use a multitiered solution, where the live data is stored on a local storage device and backups are stored on progressively “colder” storage solutions. In this solution, a cron job (or similar) backs up the live data to the second tier at regular intervals, and another job is used to back up data from that tier to another tier at slightly wider intervals.
One possible implementation of this strategy on Google Cloud Platform would be to use persistent disk for the live data tier, a standard Cloud Storage bucket for the second tier, and a Cloud Storage Nearline bucket for the final tier. In this implementation, the tiers would be connected as follows:
Configure your application to back up data to the persistent disk attached to the instance.
Set up a task, such as a cron job, to move the data to the standard Cloud Storage bucket after a defined period of time.
Finally, set up another cron job or use Cloud Storage Transfer Service to move your data from the standard bucket to the Nearline bucket.
Note: You can find Python example code for Cloud Storage Transfer Service in Cloud Platform’s GitHub repository.
The following diagram illustrates this example implementation:
Multi Tiered backup
To make this a complete disaster recovery solution, you must also implement some method of restoring your backups to a compatible version of the database. Three viable approaches are as follows:
Create a custom image that has the proper version of the database system installed.
You can then create a new Compute Engine instance with this image to test the import process. Note that this approach requires regular and rigorous testing.
Take regular snapshots of your database system.
If your database system lives on a Compute Engine persistent disk, you can take snapshots of your system each time you upgrade. If your database system goes down or you need to roll back to a previous version, you can simply create a new persistent disk from your desired snapshot and make that disk the boot disk for a new Compute Engine instance. Note that, to avoid data corruption, this approach requires you to freeze the database system’s disk while taking a snapshot.
Export the data to a highly-portable flat format such as CSV, XML, or JSON, and store it in Cloud Storage Nearline.
This approach will provide maximum flexibility, allowing you to import the data into any database system you choose to use. In addition, JSON and CSV can be easily imported into BigQuery, which will make future analysis simple and straightforward.
Note: This approach’s viability is subject to your specific compliance requirements.
Archiving directly to BigQuery
If your use case permits, you can archive real-time event data directly into BigQuery by using streaming inserts. This approach is particularly useful for performing big data analytics. To prevent accidental overwrites, you should use IAM to manage who has update and delete access to the data written to the tables.
Data corruption recovery
When database data has been corrupted, your data will need to be recovered easily and made available quickly. A good approach here is to use backups in combination with transactional log files from the corrupted database to roll back to a known-good state.
If you have chosen to use Cloud SQL, Google Cloud Platform’s fully-managed MySQL database, you should enable automated backups and binary logging for your Cloud SQL instances. This will allow you to easily perform a point-in-time recovery, which restores your database from a backup and recovers it to a fresh Cloud SQL instance. For more details, see Cloud SQL Backups and Recovery.
If you manage your own relational databases with Compute Engine, the principles remain the same, but you are responsible for managing the database service and implementing an appropriate backup process.
If you are using an append-only data store like BigQuery, there are a number of mitigating strategies you can adopt:
Export the data from BigQuery, and create a new table that contains the exported data but excludes the corrupted data.
Store your data in different tables for specific time periods. This method ensures that you will need to restore only a subset of data to a new table, rather than a whole dataset.
Store the original data on Cloud Storage. This will allow you to create a new table and reload the uncorrupted data. From there, you can adjust your applications to point to the new table.
Note: This method provides good availability, with only a small hiccup as you point your applications to the new store. However, unless you have implemented application-level controls to prevent access to the corrupted data, this method can result in inaccurate results during later analysis.
Additionally, if your RTO permits, you can prevent access to the table with the corrupted data by leaving your applications offline until the uncorrupted data has been restored to a new table.
Application recovery
It’s important to maintain high levels of uptime—if your service is unavailable, you’re losing business. This section will examine ways of failing your application over to another location as quickly as possible.
Hot standby server failover
In this solution, you have a continuously online server on standby. This server does not receive traffic while the main application server is functional.
If your service is running entirely on Google Compute Engine, you can streamline application failover by using Compute Engine’s HTTP load balancing service. The HTTP load balancer accepts traffic through a single global external IP address, and then distributes it according to forwarding rules you define. Properly configured, this service will automatically fail over to your standby server in the event that a main instance becomes unhealthy.
Important: The HTTP load balancing service can direct traffic only to Compute Engine instance groups; it cannot be used to send traffic to IPs outside your Compute Engine network.
Warm standby server failover
This solution is identical to hot standby server failover, but omits use of Compute Engine’s HTTP load balancing service in favor of manual DNS adjustment. Here, RTO is determined by how quickly you can adjust the DNS record to cut over to the standby server.
Cold standby server failover
In this solution, you have an offline application server on standby that is identical to the main application server. In the event that the main application server goes offline, the standby server is instantiated. Once it is online, traffic fails over to it.
Cold standby server example
In this example, you would run the following:
A serving instance. This instance is part of an instance group, and said group is used as a backend service for an HTTP load balancer.
A minimal instance that performs the following functions:
Runs a cron job to snapshot the serving instance at regular intervals
Checks the health of the serving instance at regular intervals
This minimal instance is part of a managed instance group, and this group is controlled by a Compute Engine autoscaler. The autoscaler is configured to keep exactly one minimal instance running at all times, utilizing an instance template to create a new instance in the event that the current running instance becomes unavailable.
If the minimal instance detects that the serving instance has been unresponsive for a specified period of time, it instantiates a new instance using the latest snapshot and adds the new instance to the managed instance group. When the new instance comes online, the HTTP load balancer begins directing traffic to it, as illustrated below:
Cold standby post-recovery state
Note: The minimal instance’s role could also be fulfilled by a lightweight Google App Engine application that uses scheduled tasks to perform Cron-like operations. See Reliable Task Scheduling on Google Compute Engine for more information.
Warm static site failover
In the unlikely event that you are unable to serve your application from Compute Engine instances, you can mitigate service interruption by having a Cloud
Storage-based static site on standby. This solution is very economical, and can be particularly effective if your website has few or no dynamic elements—in the event of failure, you can simply change your DNS settings, and you will have something serving immediately.
Warm static site example
In this example, the primary application runs on Compute Engine instances. These instances are grouped into managed instance groups, and these instance groups serve as backend services for the HTTP load balancer. The HTTP load balancer directs incoming traffic to the instances according to the load balancer configuration, the instance groups’ respective configurations, and the health of each instance.
In the normal configuration, Cloud DNS is configured to point at this primary application, and the standby static site sits dormant. In the event that the Compute Engine application is unable to serve, you would simply configure Cloud DNS to point to this static site.
Remote recovery
If your production environment is on-premises or on another cloud provider, Google Cloud Platform can be useful as a target for backups and archives. Using Carrier Interconnect, Direct Peering, and/or Compute Engine VPN, you can easily adapt the previously described disaster recovery strategies to your own situation. This section discusses methods for integrating Google Cloud Platform into your remote disaster recovery strategies.
Replicating storage with Google Cloud Platform
If you are replicating from an on-premises storage appliance, you can use Carrier Interconnect or Direct Peering to establish a connection with Google Cloud Platform, then copy your data to the storage solution of your choice. Data can then be restored to your on-premises storage or to a storage location on Google Cloud Platform.
If you are replicating from other cloud services, you might be able to use the Google Cloud Storage XML API. This API isinteroperable with some cloud storage tools and libraries that work with services such as Amazon Simple Storage Service (Amazon S3) and HP Helion Eucalyptus Storage (Walrus).
Replicating application data with Google Cloud Platform
In this scenario, production workloads are on-premises and Google Cloud Platform is the disaster recovery failover target.
One possible solution is to set up a minimal recovery suite—a cold standby application server and a hot/active database—on Google Cloud Platform, configuring the former to quickly scale up in the event that it needs to run a production workload. In this situation, the database must be kept up-to-date; however, the application servers would only be instantiated when there is a need to switch over to production. Depending on your RTO, the appropriate image starting point would be used to start and configure a working instance.
On-premises to Google Cloud Platform recovery plan
Notice that only the database server instance is running on the Google Cloud Platform side. As noted earlier, this instance must run at all times so that it can receive the replicated data.
To reduce costs, you can run the database on the smallest machine type capable of running the database service. When the on-premises application needs to fail over, you can make your database system production-ready as follows:
Destroy the minimal instance, making sure to keep the persistent disk containing your database system intact. If your system is on the boot disk, you will need to set the auto-delete state of the disk to false before destroying this instance.
Create a new instance, using a machine type that has appropriate resources for handling a production load.
Attach the persistent disk containing your database system to the new instance.
In the event of a disaster, your monitoring service will be triggered to spin up the web tier and application tier instances in Google Cloud Platform. You can then adjust the Cloud DNS record to point to the web tier or, if you are using the Compute Engine HTTP load balancing service, to the load balancer’s external IP. The following diagram illustrates the state of the overall production environment after the disaster recovery plan has been executed:
Post-recovery state
For smaller RTO values, you could adjust the above strategy by keeping all of the Compute Engine instances operational but not receiving traffic (see Warm standby server failover). This strategy is generally not cost-efficient. If your RTO does not allow for the time it would take to bootstrap from a minimal configuration, consider implementing a fully-operational environment that serves traffic both from
on-premises and from Google Cloud Platform, as illustrated below
Active/active hybrid production environment (on-premises and Google Cloud Platform)
If you choose to implement this hybrid approach, be sure to use a DNS service that supports weighted routing when routing traffic to the two production environments so that you are able to deliver the same application from both. In the event that one environment becomes unavailable, you can then disable DNS routing to the unavailable environment.
Maintaining machine image consistency
If you choose to implement an on-premises/cloud or cloud/cloud hybrid solution, you will most likely need to find a way to maintain consistency across production environments.
For a discussion of how to create an automated pipeline for continuously building images with Packer and other open source utilities, seeAutomated Image Builds with Jenkins, Packer, and Kubernetes.
If a fully-configured image is required, consider something like Packer, which can create identical machine images for multiple platforms from a single configuration
file. In the case of Packer, you can put the configuration file in version control to keep track of what version is deployed in production.
As another option, you could use configuration management tools such as Chef, Puppet, Ansible, or Saltstack to configure instances with finer granularity, creating base images, minimally-configured images, or fully-configured images as needed. For a discussion of how to use these tools effectively, see Compute Engine Management with Puppet, Chef, Salt, and Ansible.
You can also manually convert and import existing images such as Amazon AMIs, Virtualbox images, and RAW disk images to Compute Engine.
Google App Engine is a regional service and while it is replicated to all zones of a region to reduce potential downtime, it cannot span to more than a region. The recommended way to deploy your application to several regions is to use one region per project, but there is currently no good way to load balance between those projects if you use App Engine Standard.